Full-Stack Observability: Implementing Combined Metrics, Logs, and Traces for Deep Application Visibility
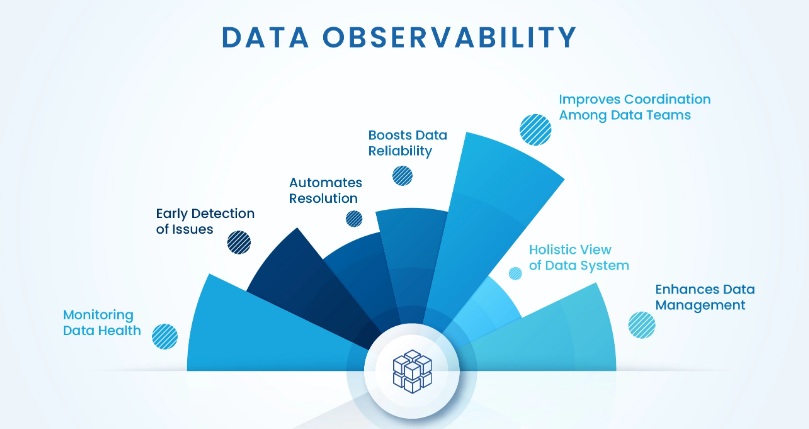
Imagine managing a sprawling city at night — thousands of lights flicker, roads intersect, and every district buzzes with its rhythm. To ensure the city functions smoothly, you’d need street-level visibility, power grid reports, and real-time traffic updates. In the world of modern software, full-stack observability serves the same purpose. It brings together metrics, logs, and traces to give developers a panoramic yet detailed view of how their systems breathe, behave, and perform.
Understanding the Symphony of Observability
Traditional monitoring is like listening to a single instrument in an orchestra — you might hear when it’s off-key, but you won’t understand how the entire symphony is performing. Observability, on the other hand, helps engineers listen to the whole composition.
Metrics provide numerical insights, like CPU load or request latency. Logs tell the story — who did what and when. Traces follow the journey of each request across services. When combined, these three layers reveal not just what went wrong, but why.
For those aspiring to master these techniques, structured learning through full stack Java developer training helps professionals understand how monitoring ties into real-world application performance and debugging. It builds the foundation to navigate complex systems confidently.
Metrics: The Pulse of the System
Metrics are like a patient’s vital signs — heartbeat, blood pressure, and temperature. They indicate health at a glance. In software, they show trends such as CPU usage, response times, and throughput.
But numbers alone can be misleading. A CPU spike doesn’t always mean trouble; it might just reflect increased user traffic. What truly matters is correlation — connecting metrics to context. Tools like Prometheus or Datadog enable this by visualising trends, helping teams distinguish between a momentary fluctuation and an actual anomaly.
Metrics aren’t just data points; they’re signals that reveal performance patterns over time, guiding proactive decision-making before minor inefficiencies grow into critical issues.
Logs: The DNA of Application Behaviour
If metrics show the heartbeat, logs reveal the patient’s story. Every line of code, every user request, every system response — it all gets recorded here. Logs are the black boxes of digital flight.
Through structured logging, developers can sift through millions of entries to trace user sessions, debug failed API calls, or identify unauthorised access attempts. Logs bridge the gap between data and diagnosis.
Modern observability stacks use log aggregation systems like ELK (Elasticsearch, Logstash, Kibana) or Loki to centralise and analyse logs efficiently. They transform chaos into clarity, allowing teams to detect recurring issues and patterns that might otherwise remain invisible.
Traces: The Journey of a Request
Traces act like a GPS tracker, following each request as it travels across microservices. They provide a complete map of interactions, showing where delays, failures, or bottlenecks occur.
In distributed architectures, where one user action might trigger dozens of service calls, tracing becomes essential. Tools like Jaeger and OpenTelemetry make it possible to visualise these paths in detail. When something slows down, traces identify exactly where the problem resides — reducing mean time to resolution (MTTR) dramatically.
This bird’s-eye view empowers developers to optimise workflows and align system components seamlessly, ensuring smooth, efficient execution across the stack.
Building an Observability-Driven Culture
Observability isn’t just a toolset — it’s a mindset. It requires collaboration between development, operations, and security teams. Each must share responsibility for system health, understanding how every layer contributes to reliability.
With the growing complexity of cloud-native environments, observability ensures resilience by enabling teams to anticipate problems rather than react to them. Investing in training, tools, and culture ensures that observability becomes a shared language across technical disciplines.
Enrolling in full stack Java developer training provides hands-on exposure to these systems — from setting up dashboards to instrumenting code with observability frameworks — ensuring that developers build, maintain, and scale applications with complete visibility.
Conclusion
Full-stack observability isn’t about collecting data — it’s about making sense of it. By combining metrics, logs, and traces, teams gain the insight to diagnose, optimise, and innovate continuously.
Just as a pilot depends on multiple instruments to navigate safely, developers rely on observability to steer their systems through the unpredictable skies of production. The ability to see deeply, act swiftly, and learn continuously defines the future of software reliability.
For today’s engineers, mastering observability is more than a skill — it’s a responsibility. In a world where every second of downtime counts, visibility is not just power; it’s survival.